
Sketech #6 Developer’s Visual Guide: API-First, Digital Signature & Smart Messaging Techniques
Explore Core Dev Concepts through a Visual Journey

Welcome back to Sketech | Visual Thinking for Devs
Exploring essential concepts is my mission, and this week, I’m covering the pillars that directly impact your workflow. From practical methodologies to foundational ideas, this edition offers insights to strengthen your technical decisions and streamline your development process.
Here’s what you’ll find:
⚡The Fastest Way to Understand API First Approach: Discover how to structure and simplify service interactions, boosting efficiency from the ground up.
⚡How Digital Signatures Work: A Practical Guide for Software Developers: Learn how to implement digital signatures to ensure the authenticity of every message and transaction.
⚡Smart Messaging Choices: Find out when and how to use each messaging method to scale your applications without compromising communication.
Each topic is presented visually to help the ideas stick and make applying them easier in your day-to-day work.
The fastest way to understand API First Approach
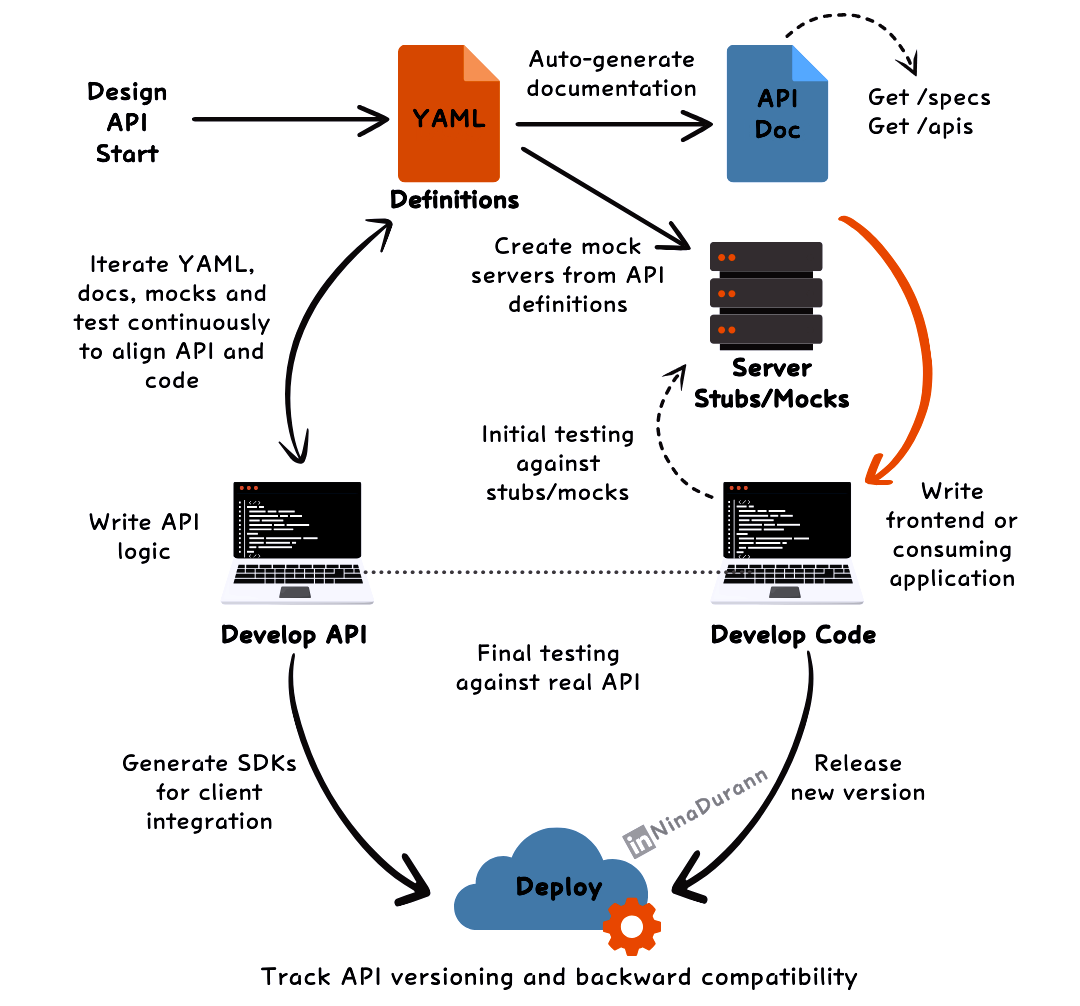
In an API First approach, defining the API comes before writing any code. This ensures that everyone (developers, testers and stakeholders) are on the same page from day one.
The process starts with creating the API definition in YAML, a file that lays out the entire structure of the API.
The YAML file becomes the source of truth.
From this, documentation is automatically generated and mock servers are created, allowing both the backend and frontend teams to develop in parallel without waiting for the API to be fully implemented.
Development teams can:
Write logic while continuously iterating on the YAML.
Use mock servers to simulate API behavior and perform initial testing.
This allows for:
Quick feedback loops as developers test their code against stubs and mocks.
Real-time updates to the API as it evolves.
Once everything is aligned, the API and the code are deployed.
Well, we may seem aligned, but here's something to think about: If it’s API First, why is a compatibility matrix and backward compatibility still necessary?
Why Compatibility and Backward Compatibility Are Needed
In an API-First approach, defining and iterating on the API structure in a YAML file indeed fosters synchronization across teams, accelerates development, and allows for seamless evolution of the API. However, a Compatibility Matrix and focus on Backward Compatibility are still essential, even in this framework, due to the dynamic nature of real-world application ecosystems.
Versioning and Consumer Integration: Even when the API is designed and documented early, APIs are often consumed by a variety of clients—both external and internal. Each client may adopt the API at a different time and pace. Consequently, as the API evolves, newer versions may introduce changes (e.g., modified response structures or endpoint behaviors) that break existing implementations for these consumers. A compatibility matrix is used to document which versions of the API support particular consumer versions, while backward compatibility ensures that existing clients remain functional even after the API changes.
Microservices and Dependent Services: In a distributed microservices architecture, each service might rely on one or more versions of the API for different purposes. Ensuring backward compatibility means these microservices continue to function reliably without necessitating constant updates across the entire ecosystem every time a change is made. This stability is especially important in parallel development, where frontend and backend teams work independently using mock servers—if the actual deployed API behaves differently due to a breaking change, issues can arise that mock environments may not catch.
Long-Term Maintenance and Support: Maintaining an API involves supporting older clients, as not all clients or services can migrate to new versions instantly. Backward compatibility provides a safeguard, allowing continued support for legacy clients without forcing immediate upgrades. Additionally, a compatibility matrix clarifies the expected behavior of various versions, helping developers and support teams manage transitions effectively and prioritize deprecations.
Agility vs. Stability Balance: In iterative and agile environments, teams frequently refine APIs to address new business requirements or technical improvements. However, if these changes are unrestricted, it can lead to instability for end-users. Therefore, balancing agility with stability through backward compatibility and a compatibility matrix allows teams to innovate while minimizing disruptions.
Thus, in an API-First approach, backward compatibility and a compatibility matrix help mitigate risk, reduce the need for immediate client refactoring, and maintain harmony across the API’s entire lifecycle, ensuring a robust experience for all users and integrations.
How Digital Signatures Work: A Practical Guide for Software Developers
As a software developer, you’ve probably heard about digital signatures, but the concept of public and private keys can be confusing if you’re not familiar with cryptography. Let’s break it down step by step:
What are Public and Private Keys? You have two keys:
Private key: Only you have it. It’s used to sign documents.
Public key: Anyone can have it. It’s used to verify that the signature is yours.
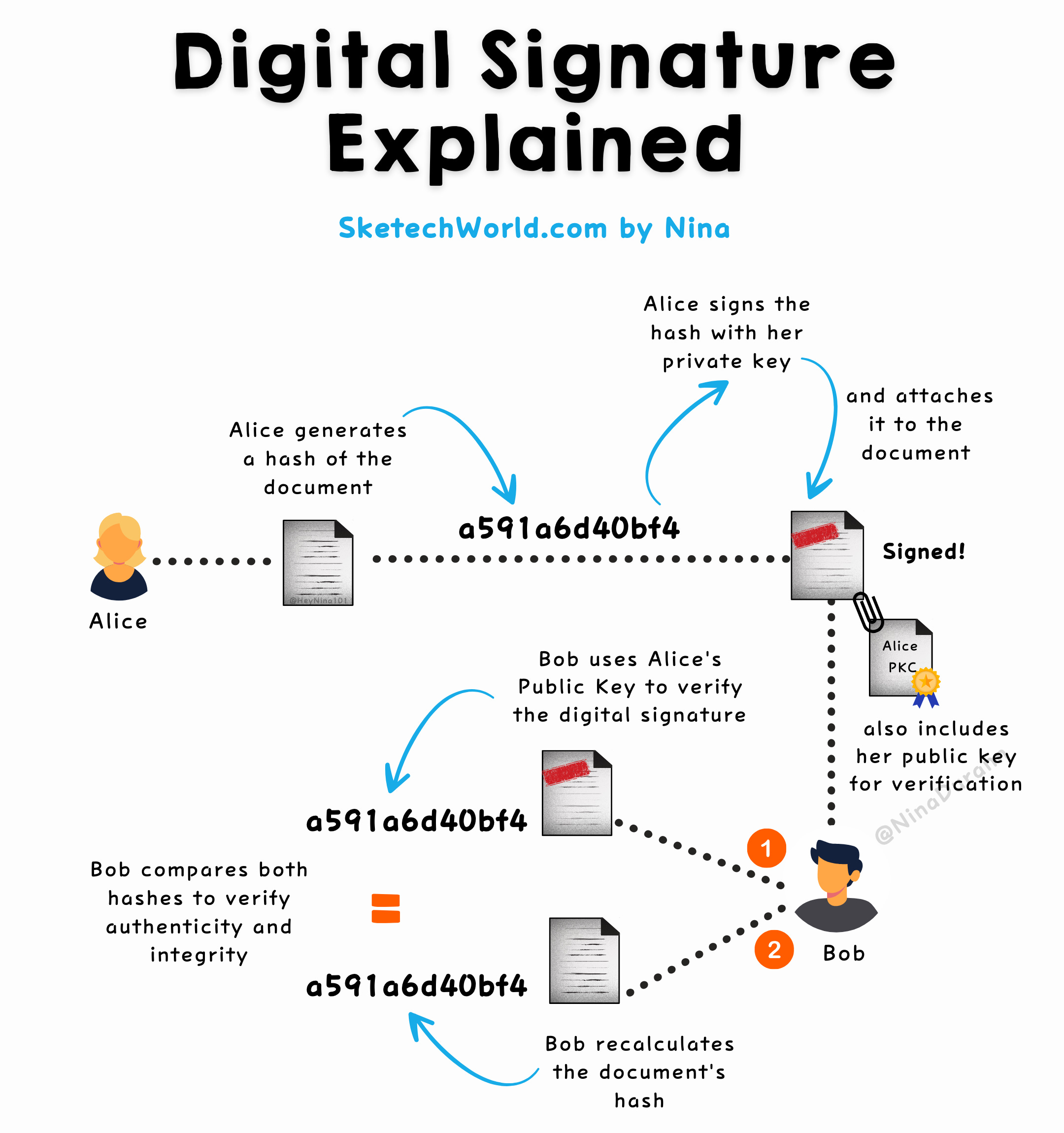
What does "Signing" mean? When you sign a document, you don’t sign the whole document. Instead:
Create a hash: A hash is a unique "fingerprint" of the document. If even a single character changes, the hash will be different.
Sign the hash: You use your private key to encrypt the hash, not the document itself. This encrypted hash is the digital signature.
So, the digital signature is really just an encrypted version of the hash.
How is the signature verified? When someone gets the document and your signature:
They use your public key to decrypt the hash that you signed.
They generate a new hash from the document.
They compare the decrypted hash from your signature with the new hash from the document.
If both hashes match, it means:
The document is authentic (it was signed by you).
The document has not been altered (it’s exactly as you signed it).
Practical Steps for Developers in Python
Generate a key pair: Use libraries like cryptography in Python to generate a public and private key pair.
Create a hash of the document: Use hash functions like SHA-256 to create a fingerprint of your document:
𝘧𝘳𝘰𝘮 𝘩𝘢𝘴𝘩𝘭𝘪𝘣 𝘪𝘮𝘱𝘰𝘳𝘵 𝘴𝘩𝘢256𝘩𝘢𝘴𝘩_𝘥𝘰𝘤𝘶𝘮𝘦𝘯𝘵 = 𝘴𝘩𝘢256(𝘥𝘰𝘤𝘶𝘮𝘦𝘯𝘵_𝘥𝘢𝘵𝘢).𝘥𝘪𝘨𝘦𝘴𝘵()Sign the hash with your private key: Use your private key to sign (encrypt) the hash:
𝘴𝘪𝘨𝘯𝘢𝘵𝘶𝘳𝘦 = 𝘱𝘳𝘪𝘷𝘢𝘵𝘦_𝘬𝘦𝘺.𝘴𝘪𝘨𝘯( 𝘩𝘢𝘴𝘩_𝘥𝘰𝘤𝘶𝘮𝘦𝘯𝘵, 𝘱𝘢𝘥𝘥𝘪𝘯𝘨.𝘗𝘚𝘚( 𝘮𝘨𝘧=𝘱𝘢𝘥𝘥𝘪𝘯𝘨.𝘔𝘎𝘍1(𝘩𝘢𝘴𝘩𝘦𝘴.𝘚𝘏𝘈256()), 𝘴𝘢𝘭𝘵_𝘭𝘦𝘯𝘨𝘵𝘩=𝘱𝘢𝘥𝘥𝘪𝘯𝘨.𝘗𝘚𝘚.𝘔𝘈𝘟_𝘓𝘌𝘕𝘎𝘛𝘏 ), 𝘩𝘢𝘴𝘩𝘦𝘴.𝘚𝘏𝘈256())Verify the signature: When you receive a document, verify it using the sender’s public key to decrypt the signature and compare hashes.
A digital signature ensures authenticity, but 𝘄𝗵𝗮𝘁 𝗶𝗳 𝘀𝗼𝗺𝗲𝗼𝗻𝗲 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝘀 𝗮 𝗳𝗮𝗸𝗲 𝗽𝘂𝗯𝗹𝗶𝗰 𝗸𝗲𝘆 associated with someone else to impersonate them? The key lies in Certification Authorities.
This scenario is known as a public key spoofing or key substitution attack, where someone distributes a fake public key and impersonates the original signer. Here’s a breakdown of how this works and how it’s mitigated:
How Public Key Spoofing Works
In a digital signature system, the recipient verifies the signature using the signer’s public key. However, if an attacker distributes a counterfeit public key, they can generate a fake signature that appears authentic when verified against the fake public key. This attack relies on the recipient trusting that the public key truly belongs to the original signer.
Mitigation Techniques
Certificate Authorities (CAs): CAs are trusted entities that issue digital certificates to verify the authenticity of public keys. A CA links an individual or organization to a specific public key by signing the key with its private key, creating a certificate. When the recipient receives a signature, they can check the certificate to ensure the public key belongs to the intended signer.
Public Key Infrastructure (PKI): PKI combines CAs, policies, and protocols to securely distribute, verify, and revoke public keys. By using PKI, systems ensure that the public key associated with a signer is legitimate. For instance, HTTPS and email encryption rely on PKI to prevent impersonation.
Web of Trust: In decentralized systems (like PGP), a Web of Trust model allows users to vouch for each other's identities by cross-signing public keys. This model, however, requires manual verification steps and is often used in smaller, trusted networks.
By relying on these mechanisms, systems ensure that recipients can trust the public key’s origin, reducing the risk of an attacker distributing a fake key to impersonate others.
Smart Messaging Choices

↳ Queue: One-to-One Communication
- A queue delivers each message to one receiver.
- Once the message is received, it’s removed from the queue, avoiding duplicates.
- Use it when only one service should process the message and you want to prevent duplicate processing.
↳ Topic: One-to-Many Broadcasting
- A topic sends the same message to multiple subscribers.
- Messages stay in the topic until all active subscribers receive them.
- Perfect for scenarios where many services need the same data.
↳ When to Use Each
- Use Queues for tasks that need to be handled by a single worker, like processing payments, and to avoid duplicate tasks.
- Use Topics when you want to broadcast updates, like sending a notification to all users.
If queues and topics are different, maybe choosing between Kafka and RabbitMQ deserves some thought?
Choosing between Kafka and RabbitMQ depends largely on your use case and message handling requirements.
Message Delivery and Durability:
RabbitMQ is a message broker designed for complex routing and queuing. It’s ideal for tasks needing reliable one-to-one messaging or strict message ordering, such as task queues (think payment processing or single-worker tasks). RabbitMQ uses the Advanced Message Queuing Protocol (AMQP) and is optimized for durability and consistency, making it suitable for real-time, single-consumer scenarios where every message must be processed once.
Kafka is a distributed streaming platform optimized for high-throughput, distributed data pipelines. Kafka is often chosen when the goal is to stream large volumes of data across multiple consumers simultaneously (broadcasting), as it efficiently handles one-to-many use cases. It uses a commit log for message storage, meaning messages are retained for a defined period even after being read, allowing for asynchronous processing and reprocessing.
Use Case Suitability:
RabbitMQ is best suited for applications where real-time task handling with strong guarantees on message processing order and reliability are essential. If you need strict message acknowledgment (ACK) and control over consumer acknowledgment and reprocessing, RabbitMQ excels here.
Kafka is preferred in data streaming and logging scenarios where multiple services or applications need the same data at the same time. Its performance scales well for analytics pipelines, event sourcing, and other large-scale data processing tasks where quick access to historical data is a priority.
Scalability and Throughput:
Kafka offers better scalability for massive data throughput, as it’s built with partitioned log structures that allow parallel consumption across multiple nodes, which is ideal for high-velocity data and distributed environments.
RabbitMQ can scale but generally requires more complex clustering and is better suited for message queuing with lower throughput requirements compared to Kafka.
In summary, use RabbitMQ for scenarios involving strict task distribution, where messages must be processed exactly once and in order. Use Kafka for broadcasting to multiple consumers or for handling high-throughput data streams, especially where historical message access is important.
And that’s a wrap for this week’s deep dive! I hope these visuals brought clarity to some key concepts that can streamline your projects.
Until next time, keep building and optimizing.